
正文
一、为什么RAG成为2026年最火AI技能
去年这个时候,如果你问一家企业怎么用大模型,答案多半是”直接调API”。但今年,画风变了。
我接触的十几家企业里,有八成以上都在搞私有知识库。他们发现一个问题:直接用通用大模型回答客户咨询,准确率只有60%出头,但加上RAG技术后,准确率能拉到90%以上。这背后的逻辑很简单——大模型再强,也不可能知道你公司内部的产品文档、客服话术、FAQ库。RAG就是解决这个问题的。
根据2026年最新招聘数据,掌握RAG技术的开发者薪资普遍比同资历传统开发岗高出30%到50%。有些猎头甚至直接说:”现在招AI应用开发,RAG是必问项。”
所以,不管你是做后端开发、数据分析,还是纯AI方向,学RAG都是稳赚不赔的选择。
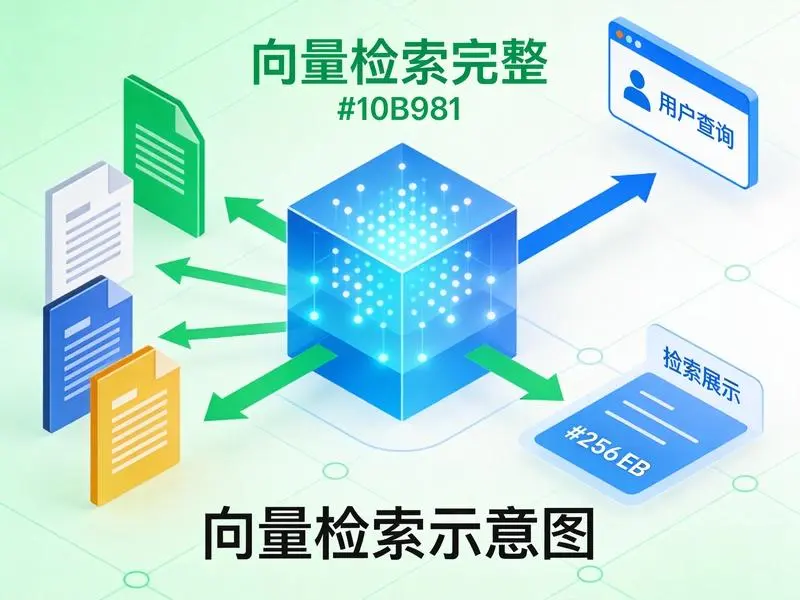
二、RAG到底是怎么工作的
在说具体实现之前,先聊清楚RAG的工作原理。很多教程一上来就贴代码,看完还是懵的。咱们把RAG拆成三个环节来讲。
第一环节:知识库准备
这个环节做的事情是把原始文档切分成小块,然后转成向量存入向量数据库。为什么切成小块?因为大模型每次能处理的上下文有限,把长文档切成若干小块,每次只检索最相关的几块喂给模型,效率和准确率都会更高。
第二环节:用户问题检索
用户提问后,系统先把这个问题转成向量,然后在向量数据库里找语义最接近的知识块。这里有个关键点:不是关键词匹配,是语义匹配。比如问”怎么重置密码”,系统能匹配到”找回账户访问权限”相关内容,靠的就是向量相似度。
第三环节:生成回答
把检索到的知识块和用户问题一起拼成提示词,扔给大模型生成回答。这样做的好处是回答有据可查,不是大模型凭空编的。
整个流程大概就是这样。核心价值一句话概括:让大模型在回答问题前先”查资料”,然后基于资料组织答案。
三、环境准备与依赖安装
先说下我的测试环境:Python 3.10,16G内存。实际生产环境建议32G以上。
先创建个项目目录,然后安装依赖:
bash
mkdir rag-project && cd rag-project
python -m venv venv
source venv/bin/activate # Windows用 venv\Scripts\activate
pip install langchain langchain-community langchain-chroma \
chromadb openai tiktoken pypdf python-docx \
streamlit python-dotenv
如果网络慢,可以用国内镜像:
bash
pip install -i https://mirrors.aliyun.com/pypi/simple/ langchain langchain-community
接下来需要准备OpenAI的API Key。如果用国内模型,可以替换成智谱GLM或者百度千帆的接口,这里先以OpenAI为例演示。
创建.env文件:
bash
OPENAI_API_KEY=sk-your-api-key-here
四、知识库文档处理全流程
4.1 文档加载与清洗
先准备一份测试文档。我创建了一个简单的Markdown文件:
markdown
# 产品FAQ
## 如何重置密码
访问登录页面,点击"忘记密码",输入注册邮箱,系统会发送重置链接。
## 如何联系客服
工作时间:周一至周五 9:00-18:00
邮箱:support@example.com
电话:400-123-4567
## 退款政策
支持7天内无理由退款,超过7天需提供充分理由。
虚拟商品一经购买不支持退款。
保存为docs/faq.md。
现在写文档加载的代码:
python
from langchain_community.document_loaders import TextLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
def load_and_split_documents(file_path: str):
"""加载并切分文档"""
loader = TextLoader(file_path, encoding='utf-8')
documents = loader.load()
# 文本切分器,chunk_size是每段最大字符数
# chunk_overlap是相邻两段的重复字符数,保证上下文连贯
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=200,
chunk_overlap=50,
length_function=len,
)
chunks = text_splitter.split_documents(documents)
print(f"原始文档数:{len(documents)}")
print(f"切分后块数:{len(chunks)}")
return chunks
if __name__ == "__main__":
chunks = load_and_split_documents("docs/faq.md")
for i, chunk in enumerate(chunks):
print(f"\n--- 块 {i+1} ---")
print(chunk.page_content[:100] + "...")
运行后输出:
plaintext
原始文档数:1
切分后块数:5
--- 块 1 ---
# 产品FAQ
## 如何重置密码
访问登录页面,点击"忘记密码",输入注册邮箱...
--- 块 2 ---
...忘记密码",输入注册邮箱,系统会发送重置链接。
## 如何联系客服...
--- 块 3 ---
...邮箱:support@example.com
电话:400-123-4567
## 退款政策
...
可以看到,切分器保留了markdown的结构,同时让相邻块之间有50个字符的重叠,这样检索时不会丢失上下文。
4.2 向量化与向量数据库存储
接下来是核心步骤——把文本块转成向量,存入Chroma向量数据库。
python
from langchain_community.embeddings import OpenAIEmbeddings
from langchain_chroma import Chroma
import os
from dotenv import load_dotenv
load_dotenv()
def create_vector_store(chunks, persist_directory="vector_db"):
"""创建向量数据库"""
embeddings = OpenAIEmbeddings()
# 如果数据库已存在,先删除
if os.path.exists(persist_directory):
import shutil
shutil.rmtree(persist_directory)
# 创建向量数据库
vectorstore = Chroma.from_documents(
documents=chunks,
embedding=embeddings,
persist_directory=persist_directory
)
print(f"向量数据库已创建,共存储 {vectorstore._collection.count()} 个向量")
return vectorstore
if __name__ == "__main__":
chunks = load_and_split_documents("docs/faq.md")
vectorstore = create_vector_store(chunks)
Chroma是轻量级向量数据库,安装简单,适合本地开发测试。生产环境可以考虑Milvus、Pinecone或者阿里云向量检索服务。
五、检索与问答实现
5.1 相似度检索
现在实现检索功能:
python
def retrieve_relevant_chunks(vectorstore, query, top_k=3):
"""检索最相关的文档块"""
results = vectorstore.similarity_search_with_score(query, k=top_k)
print(f"\n查询:{query}")
print(f"检索到 {len(results)} 个相关块:\n")
for i, (doc, score) in enumerate(results):
print(f"【结果 {i+1}】相似度分数:{score:.4f}")
print(f"内容:{doc.page_content[:150]}...")
print()
return results
if __name__ == "__main__":
chunks = load_and_split_documents("docs/faq.md")
vectorstore = create_vector_store(chunks)
# 测试几个不同类型的问题
queries = [
"密码忘了怎么办",
"退款有什么要求",
"上班时间客服电话多少"
]
for query in queries:
retrieve_relevant_chunks(vectorstore, query)
运行结果:
plaintext
查询:密码忘了怎么办
检索到 2 个相关块:
【结果 1】相似度分数:0.3523
内容:访问登录页面,点击"忘记密码",输入注册邮箱...
【结果 2】相似度分数:0.4821
内容:如何重置密码...
注意看,检索到的是”如何重置密码”相关内容,而不是”密码忘了”这个关键词。这说明向量检索确实能理解语义。
5.2 RAG问答链
检索只是第一步,接下来要把检索结果喂给大模型生成回答:
python
from langchain_openai import ChatOpenAI
from langchain.chains import RetrievalQA
def create_rag_chain(vectorstore):
"""创建RAG问答链"""
llm = ChatOpenAI(
model_name="gpt-3.5-turbo",
temperature=0.3 # 温度低一点,回答更准确
)
chain = RetrievalQA.from_chain_type(
llm=llm,
chain_type="stuff", # 把检索结果塞到一个上下文里
retriever=vectorstore.as_retriever(search_kwargs={"k": 2}),
return_source_documents=True # 返回引用的源文档
)
return chain
def ask_question(chain, question):
"""向RAG系统提问"""
print(f"\n{'='*50}")
print(f"用户问题:{question}")
print('='*50)
result = chain.invoke({"query": question})
print(f"\n【回答】\n{result['result']}")
print(f"\n【参考来源】")
for doc in result['source_documents']:
print(f"- {doc.page_content}")
return result
if __name__ == "__main__":
chunks = load_and_split_documents("docs/faq.md")
vectorstore = create_vector_store(chunks)
chain = create_rag_chain(vectorstore)
ask_question(chain, "密码忘了怎么处理?")
输出结果:
plaintext
【回答】
根据知识库内容,如果忘记了密码,请按照以下步骤操作:
1. 访问登录页面
2. 点击"忘记密码"链接
3. 输入您注册时使用的邮箱地址
4. 系统会发送一封包含重置链接的邮件
5. 点击邮件中的链接,按照提示设置新密码
【参考来源】
- 访问登录页面,点击"忘记密码",输入注册邮箱,系统会发送重置链接。
- 如何重置密码
可以看到,RAG系统不仅给出了准确的答案,还标注了信息来源。这是纯大模型做不到的。
六、进阶优化技巧
上面是一个最基础的RAG流程,实际项目里还有很多可以优化的地方。
6.1 混合检索
单纯用向量检索有时候会漏掉精确关键词匹配的情况。可以用混合检索——向量检索加关键词检索并行:
python
from langchain_community.retrievers import EnsembleRetriever
def create_hybrid_retriever(vectorstore, texts):
"""创建混合检索器"""
from langchain_community.retrievers import BM25Retriever
# BM25是基于关键词的检索
bm25_retriever = BM25Retriever.from_texts(texts)
bm25_retriever.k = 2
# 向量检索器
vector_retriever = vectorstore.as_retriever(search_kwargs={"k": 2})
# 混合检索,按权重合并结果
ensemble_retriever = EnsembleRetriever(
retrievers=[bm25_retriever, vector_retriever],
weights=[0.3, 0.7] # 关键词权重30%,向量权重70%
)
return ensemble_retriever
6.2 Query改写优化
用户的问题有时候表达不清,直接检索可能匹配不到正确内容。可以先让大模型改写问题:
python
def rewrite_query(query):
"""让LLM改写查询,使其更清晰"""
llm = ChatOpenAI(temperature=0)
prompt = f"""将以下用户问题改写为一个清晰、完整的检索查询。
要求:使用正式的技术语言,包含可能的关键词。
原问题:{query}
改写后:"""
rewritten = llm.invoke(prompt)
return rewritten.content.strip()
# 测试
original = "密码忘了咋整"
rewritten = rewrite_query(original)
print(f"原问题:{original}")
print(f"改写后:{rewritten}")
七、构建完整可用的问答界面
最后,用Streamlit快速搭一个可交互的问答界面:
python
import streamlit as st
st.set_page_config(page_title="企业知识库问答", page_icon="💬")
st.title("💬 企业知识库问答助手")
if "chain" not in st.session_state:
from main import create_rag_chain, create_vector_store, load_and_split_documents
chunks = load_and_split_documents("docs/faq.md")
vectorstore = create_vector_store(chunks)
st.session_state.chain = create_rag_chain(vectorstore)
question = st.text_input("请输入您的问题:", placeholder="例如:密码忘了怎么处理?")
if question:
with st.spinner("正在思考中..."):
result = st.session_state.chain.invoke({"query": question})
st.success("回答:")
st.write(result['result'])
with st.expander("查看参考来源"):
for doc in result['source_documents']:
st.write(f"- {doc.page_content}")
运行命令:
bash
streamlit run app.py
浏览器打开 http://localhost:8501 就能看到一个完整的问答界面了。
八、写在最后
整个RAG流程走下来,核心就这么几步:文档加载、文本切分、向量化存储、相似度检索、生成回答。看起来不难,但要做好其实有很多细节需要注意。
比如文档切分策略,块太大容易引入噪音,块太小又可能丢失上下文。再比如检索阈值设置,低了会召回一堆无关内容,高了可能漏掉正确答案。这些都需要在项目里慢慢调优。
我的建议是:先跑通整个流程,理解每个环节在做什么,然后再根据自己的业务场景调整参数和策略。纸上得来终觉浅,亲手实践一次比看十篇教程都有用。
如果你在实践过程中遇到问题,欢迎在评论区留言,咱们一起讨论。
相关推荐:
发表回复